最新发布第8页
排序

Dify前端样式修改
MAMP Pro 7.x + PhpStorm 调试 PHP 代码
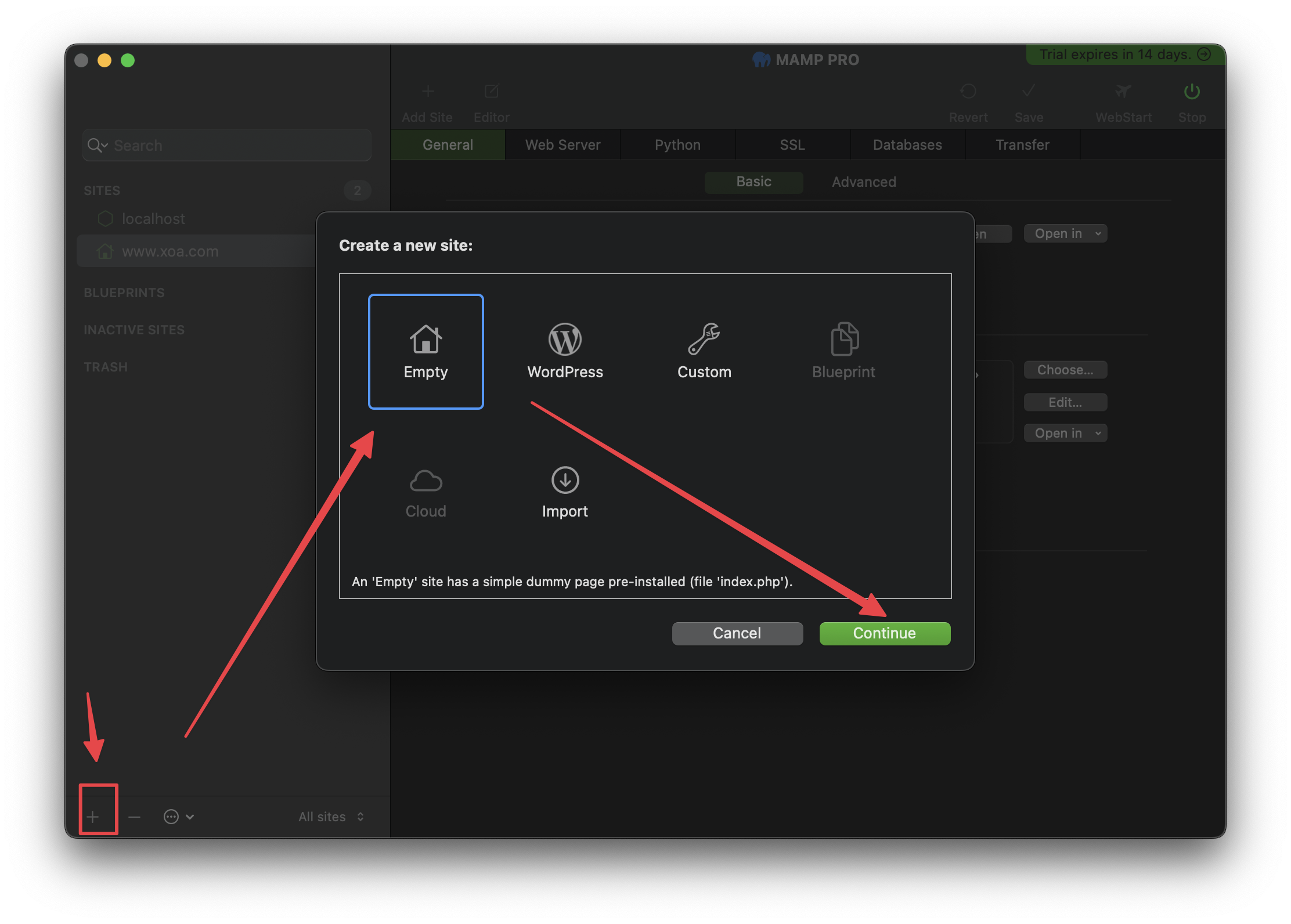
MAMP Pro 创建站点 按照下图的指示创建一个新的站点 创建新站点 在弹出的窗口中,输入站点Name以及项目的Site folder。 填写站点信息 空站点创建完成之后,配置站点的基本信息,比如 PHP 版本、...
LLM 概述
AI 技术名词 AI 中常见的技术名词如下 人工智能:AI - Artificial Intelligence 大语言模型:LLM - Large Language Model 自然语言处理:NLP - Natural Language Processing 机器学习:ML - Mac...

N-Gram 模型
将文本分割成连续的 N 个词的组合(即 N-Gram),来近似描述词序列的联合概率。基于前 N-1 个词来预测序列的第 N个词。 以词为Gram(元素)的 N-Gram模型如下图所示,其中 Unigram 中 N 值为 1,...
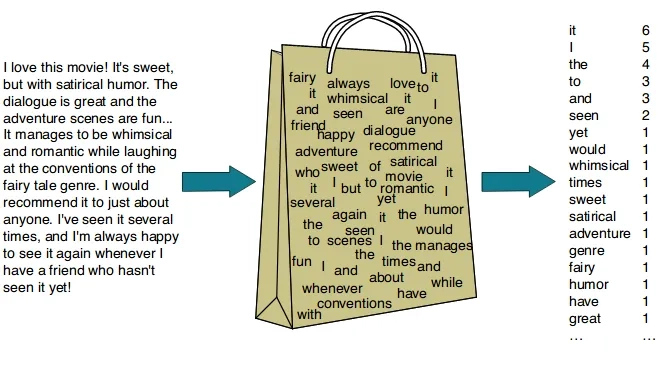
Bag-of-Words 模型
Bag-of-Words (BoW) 模型又称词袋模型。它将文本中的词看做是一个个独立的个体,不考虑它们在句子中的顺序,只关心每个词出现的频次。词袋模型会将句子表示成向量,通过比较向量之间的相似度,...

macOS Python 多版本管理
安装 Homebrew Homebrew 的官网 https://brew.sh/ 在终端输入以下命令进行安装 /bin/bash -c '$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)' 安装完成后...
词的向量表示
词向量 vs 词嵌入 词向量( Word Vector ) 通常也叫词嵌入(Word Embeding),是一种寻找词语词之间相似性的 NLP 技术。它把词汇各个维度上的特征用数值向量进行表示,利用这些维度上特征的相似...

Day 1 – Python 变量与数据管理
打印 Python 中的打印语句 print('Hello world!') 字符串操作 字符串连接 字符串的连接可以使用+操作符 print('Hello' + ' ' + 'world!') 字符串长度 字符串的长度计算,使用len()函数 输入函数...
Day 2 – 理解数据类型和字符串操作
基本数据类型 String 字符串下标 字符串的下标 Subscripting可以提取字符串特定位置的字符。 # 提取第一个字符 print('Hello'[0]) # H # 提取最后一个字符 print('Hello'[len('Hello') - 1]) # ...
matplotlib 中文显示
在 PyChorm 中使用利用虚拟环境进行matplotlib绘制图像中显示中文。 下载字体 使用 SimHei字体,点击此处链接进行字体下载。 ttf文件存储位置 进入 Python 脚本,执行以下操作 >>> imp...
